

Poufne przetwarzanie danych (ang. confidential computing) to technologia, która chroni informacje nie tylko wtedy, gdy są zapisane na dysku lub przesyłane przez sieć, ale także w najtrudniejszym momencie: podczas aktywnego przetwarzania.
Ma to szczególne znaczenie w erze AI, bo modele coraz częściej analizują dokumenty firmowe, dane klientów, informacje finansowe, dokumentację medyczną i inne poufne zasoby. Confidential computing AI pomaga ograniczyć ryzyko, że dane w użyciu zostaną podejrzane, przechwycone lub wykorzystane poza zaufanym środowiskiem.
W tym artykule wyjaśniamy, jak działa confidential computing, czym są dane w użyciu i dlaczego poufne przetwarzanie danych może stać się jednym z fundamentów bezpiecznej sztucznej inteligencji.
Czym jest poufne przetwarzanie danych?
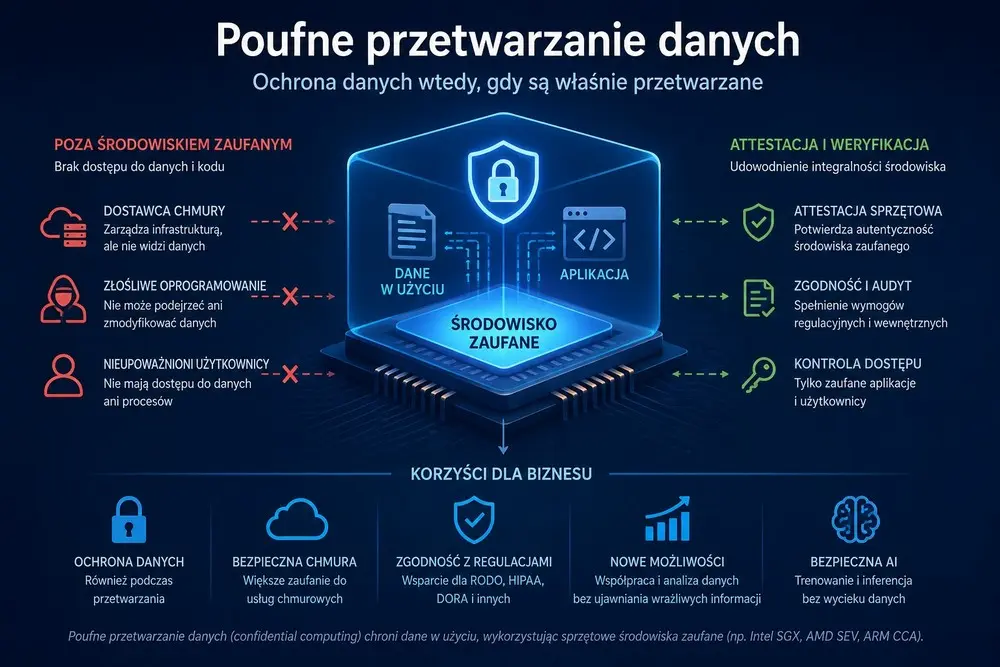
Poufne przetwarzanie danych to model bezpieczeństwa, w którym obliczenia wykonywane są w sprzętowo izolowanym, weryfikowalnym środowisku zaufanym. W praktyce oznacza to, że dane mogą być przetwarzane w chmurze, centrum danych, środowisku hybrydowym lub na współdzielonej infrastrukturze, ale dostęp do nich jest ograniczony nawet dla administratora systemu, operatora chmury czy innych procesów działających na tym samym serwerze.
Angielski termin confidential computing jest dziś powszechnie używany w dokumentacji dostawców chmury, raportach analitycznych i materiałach branżowych. W języku polskim najlepiej oddaje go właśnie określenie poufne przetwarzanie danych, ponieważ sednem technologii jest ochrona informacji podczas ich aktywnego użycia.
Najprościej można ująć to tak: tradycyjne szyfrowanie chroni dane, gdy są zapisane lub przesyłane. Poufne przetwarzanie danych chroni je wtedy, gdy system musi je odszyfrować, odczytać i wykorzystać do wykonania konkretnej operacji.
To bardzo ważna różnica. W klasycznym modelu bezpieczeństwa firmy koncentrowały się głównie na danych „w spoczynku” oraz danych „w transmisji”. Dane zapisane w bazie można zaszyfrować. Dane przesyłane przez internet można zabezpieczyć protokołem TLS. Ale gdy aplikacja, model AI lub system analityczny zaczyna faktycznie pracować na danych, pojawia się trzeci, najtrudniejszy obszar: dane w użyciu.
Właśnie ten moment przez lata był jednym z największych wyzwań cyberbezpieczeństwa. Dane muszą trafić do pamięci operacyjnej, procesora, aplikacji albo modelu AI. Muszą zostać użyte. A skoro są używane, mogą być potencjalnie narażone na podgląd, atak, błąd konfiguracji lub dostęp nieuprawnionych komponentów infrastruktury.
Dane w spoczynku, dane w transmisji i dane w użyciu – najważniejsza różnica
Aby dobrze zrozumieć, po co powstało poufne przetwarzanie danych, trzeba rozdzielić trzy stany informacji.
Dane w spoczynku to informacje zapisane na nośnikach. Mogą to być pliki, bazy danych, kopie zapasowe, archiwa, dokumenty, zdjęcia, nagrania, logi systemowe, dane klientów, dane medyczne, faktury, dane finansowe albo modele AI. Ten stan danych zabezpiecza się najczęściej przez szyfrowanie dysków, baz danych, storage’u obiektowego i kopii zapasowych.
Dane w transmisji to informacje przesyłane między systemami. Przykładem jest komunikacja między przeglądarką a serwerem, aplikacją mobilną a API, systemem płatności a bankiem, firmową aplikacją a chmurą albo usługą AI a wewnętrzną bazą danych. Ten etap zabezpieczają szyfrowane połączenia, certyfikaty, VPN, TLS i mechanizmy uwierzytelniania.
Najtrudniejsze są jednak dane w użyciu. To informacje, które są właśnie przetwarzane przez aplikację, procesor, pamięć operacyjną, model AI, system analityczny albo algorytm decyzyjny. System musi je odczytać, porównać, przeliczyć, sklasyfikować, podsumować lub wykorzystać do wygenerowania odpowiedzi.
Dane w użyciu są centralnym problemem, który rozwiązuje poufne przetwarzanie danych.
Bez ich ochrony firma może mieć zaszyfrowaną bazę danych i bezpieczną transmisję, ale nadal pozostaje luka w momencie, w którym dane są aktywnie przetwarzane. To trochę tak, jakby dokument był bezpieczny w sejfie i bezpieczny podczas transportu, ale narażony dokładnie wtedy, gdy ktoś wyjmuje go na biurko i zaczyna czytać.
Dlaczego klasyczne szyfrowanie już nie wystarcza?
Klasyczne szyfrowanie jest podstawą cyberbezpieczeństwa, ale nie rozwiązuje całego problemu. Większość systemów musi w pewnym momencie odszyfrować dane, aby wykonać na nich operację.
Jeżeli aplikacja bankowa ma sprawdzić historię transakcji klienta, musi odczytać odpowiednie rekordy. Jeżeli model AI ma podsumować dokument prawny, musi dostać dostęp do jego treści. Jeżeli system medyczny ma porównać wyniki badań, musi je przetworzyć. Jeżeli algorytm antyfraudowy ma wykryć podejrzaną płatność, musi przeanalizować jej parametry.
Szyfrowanie danych na dysku nie oznacza automatycznie, że dane są chronione w pamięci operacyjnej. Szyfrowanie transmisji nie oznacza, że dane są bezpieczne wewnątrz środowiska, które je odbiera i przetwarza.
W tradycyjnym modelu organizacja musi ufać wielu elementom infrastruktury. W grę wchodzą system operacyjny, hypervisor, administratorzy, dostawca chmury, warstwa zarządzania, biblioteki, inne procesy działające na tym samym serwerze i mechanizmy wirtualizacji. Każdy z tych elementów może stać się potencjalnym punktem ryzyka.
Poufne przetwarzanie danych ogranicza zakres zaufania. Zamiast zakładać, że cała infrastruktura jest bezpieczna, technologia koncentruje się na konkretnym, odizolowanym środowisku wykonawczym, w którym dane są chronione podczas użycia.
To podejście dobrze pasuje do współczesnej chmury, AI i modelu zero trust. Coraz trudniej zakładać, że cała infrastruktura jest „swoja”, zamknięta i w pełni kontrolowana. Firmy korzystają z publicznych chmur, zewnętrznych API, narzędzi SaaS, platform AI, rozproszonych zespołów i wielu dostawców. Dane przepływają przez więcej systemów niż kiedykolwiek wcześniej.
W takim świecie ochrona danych w użyciu przestaje być dodatkiem, a zaczyna być warunkiem bezpiecznego skalowania nowoczesnych usług.
Jak działa poufne przetwarzanie danych?
Sercem poufnego przetwarzania danych jest Trusted Execution Environment, czyli TEE. Po polsku można opisać to jako zaufane środowisko wykonawcze. Jest to odizolowany obszar, w którym aplikacja, kod lub workload mogą działać oddzielnie od reszty systemu.
TEE ma chronić dane i kod przed dostępem z zewnątrz. Oznacza to, że nawet uprzywilejowane komponenty, takie jak system operacyjny hosta, hypervisor, administrator infrastruktury czy inne maszyny wirtualne, nie powinny mieć swobodnego wglądu w to, co dzieje się wewnątrz zaufanego środowiska.
W uproszczeniu proces wygląda tak:
Najpierw aplikacja lub workload uruchamiany jest w izolowanym środowisku. Następnie następuje atestacja, czyli techniczne potwierdzenie, że środowisko jest prawidłowe, zgodne z oczekiwaniami i nie zostało podmienione. Dopiero po takiej weryfikacji system może uzyskać dostęp do kluczy, danych lub operacji potrzebnych do wykonania zadania.
Dane trafiają do chronionego środowiska, są tam przetwarzane, a na zewnątrz wychodzi tylko zatwierdzony wynik. Reszta infrastruktury nie powinna mieć możliwości podejrzenia danych w trakcie pracy.
Najważniejsza idea poufnego przetwarzania danych jest prosta: dane mogą być użyte, ale nie powinny być widoczne dla wszystkiego, co znajduje się poza zaufanym środowiskiem.
To nie oznacza absolutnej odporności na każdy możliwy atak. Żadna technologia nie daje takiej gwarancji. Oznacza jednak istotne ograniczenie powierzchni ataku i zmniejszenie liczby elementów, którym trzeba ufać.
Czym jest atestacja i dlaczego ma tak duże znaczenie?
Atestacja to jeden z kluczowych elementów poufnego przetwarzania danych. Bez niej użytkownik, aplikacja lub organizacja musieliby po prostu uwierzyć, że dane trafiają do właściwego środowiska. Z atestacją można to technicznie zweryfikować.
Atestacja pozwala potwierdzić, że aplikacja działa w prawidłowym zaufanym środowisku wykonawczym, na właściwej platformie sprzętowej, z oczekiwanym kodem i konfiguracją.
To szczególnie ważne w chmurze i AI. Firma może nie kontrolować fizycznego serwera, ale może chcieć wiedzieć, czy jej dane są przetwarzane przez zweryfikowany kod w izolowanym środowisku. Dopiero po takim potwierdzeniu można dopuścić odszyfrowanie danych, wydanie klucza lub wykonanie operacji.
W świecie sztucznej inteligencji ma to ogromne znaczenie. Jeżeli przedsiębiorstwo przekazuje do modelu dane klientów, dokumenty prawne, dane finansowe, dokumentację medyczną albo tajemnice przedsiębiorstwa, nie wystarczy deklaracja, że „system jest bezpieczny”. Potrzebny jest techniczny mechanizm sprawdzenia, gdzie trafiają dane i jaki kod je przetwarza.
W poufnym przetwarzaniu danych zaufanie nie powinno być wyłącznie obietnicą. Powinno być możliwe do technicznego potwierdzenia.
To podejście dobrze współgra z architekturą zero trust. System nie zakłada z góry, że infrastruktura jest bezpieczna. Zamiast tego weryfikuje środowisko, ogranicza dostęp i dopiero potem pozwala na pracę z danymi.
Dlaczego poufne przetwarzanie danych jest tak ważne dla AI?
Sztuczna inteligencja radykalnie zwiększa znaczenie ochrony danych w użyciu. W klasycznych aplikacjach poufne informacje trafiały zwykle do określonych systemów: CRM, ERP, bankowości elektronicznej, systemów medycznych, hurtowni danych czy narzędzi analitycznych. W erze generatywnej AI dane zaczynają przepływać przez modele językowe, agentów AI, systemy RAG, platformy automatyzacji, chmurowe API i pipeline’y treningowe.
To tworzy nowe ryzyka.
Model AI może analizować dokumenty firmowe. Agent AI może mieć dostęp do poczty, kalendarza, CRM-u, repozytorium plików, systemu fakturowania i narzędzi projektowych. System RAG może pobierać informacje z wewnętrznej bazy wiedzy. Model branżowy może być trenowany lub dostrajany na danych, których firma nie chce ujawniać dostawcy chmury, partnerowi technologicznemu ani konkurencji.
Im bardziej AI wchodzi w realne procesy biznesowe, tym większe znaczenie ma ochrona danych podczas przetwarzania.
Właśnie dlatego fraza poufne przetwarzanie danych w AI będzie pojawiać się coraz częściej. Nie chodzi już tylko o teoretyczne cyberbezpieczeństwo, ale o praktyczny warunek wdrażania sztucznej inteligencji w sektorach regulowanych: bankowości, medycynie, ubezpieczeniach, administracji, energetyce, przemyśle i usługach profesjonalnych.
Bez takiej ochrony firmy mogą mieć problem z używaniem AI na najbardziej wartościowych danych. A bez tych danych modele często pozostają tylko efektownym dodatkiem, a nie realnym narzędziem operacyjnym.
Największa wartość AI zaczyna się tam, gdzie model może pracować na danych firmowych. Największe ryzyko zaczyna się dokładnie w tym samym miejscu.
Poufne przetwarzanie danych w AI – przykładowy scenariusz
Wyobraźmy sobie firmę medyczną, która chce wykorzystać model AI do analizy dokumentacji pacjentów. Dane są bardzo wrażliwe, objęte regulacjami i nie mogą być swobodnie przekazywane zewnętrznym dostawcom. Jednocześnie AI może pomóc w klasyfikacji dokumentów, wyszukiwaniu zależności, przygotowywaniu streszczeń i wspieraniu personelu.
W klasycznym modelu firma musi zaufać dostawcy infrastruktury, aplikacji, modelu i całemu środowisku przetwarzania. W modelu poufnego przetwarzania danych informacje mogą być analizowane w sprzętowo izolowanym środowisku, a dostęp do nich uzyskuje tylko zweryfikowany kod.
Podobny scenariusz można zastosować w bankowości. Bank chce używać AI do wykrywania nadużyć, analizy transakcji lub obsługi klientów, ale nie chce, aby dane finansowe były widoczne dla nieuprawnionych elementów infrastruktury. Poufne przetwarzanie danych pozwala ograniczyć ryzyko podczas samej analizy.
Jeszcze inny przykład to kancelaria prawna. Model AI może streszczać umowy, analizować dokumenty procesowe albo porównywać zapisy kontraktowe, ale treść dokumentów nie powinna opuszczać kontrolowanego środowiska. W takim przypadku ochrona danych w użyciu jest równie ważna jak szyfrowanie archiwum dokumentów.
Najważniejszy sens tej technologii nie polega na tym, że AI staje się bezpieczna z definicji. Chodzi o to, że przetwarzanie danych przez AI może być lepiej izolowane, lepiej kontrolowane i lepiej weryfikowalne.
Jak poufne przetwarzanie danych chroni modele AI?
W rozmowie o AI często skupiamy się na danych wejściowych: promptach, dokumentach, danych klientów, rekordach medycznych czy zbiorach treningowych. Ale w wielu przypadkach równie cenny jest sam model.
Model AI może zawierać własność intelektualną firmy. Może być wytrenowany na kosztownych danych. Może odzwierciedlać unikalną wiedzę branżową. Może zawierać specjalistyczne dostrojenie, którego odtworzenie byłoby drogie i czasochłonne. W przypadku modeli medycznych, finansowych, prawnych lub przemysłowych ochrona wag modelu i konfiguracji inference może być tak samo ważna jak ochrona danych użytkownika.
Poufne przetwarzanie danych może chronić nie tylko dane wejściowe, ale także kod, parametry modelu, zapytania użytkowników, prompty systemowe i wyniki przetwarzania.
To szczególnie istotne przy korzystaniu z akceleratorów AI. Nowoczesne modele potrzebują ogromnej mocy obliczeniowej, a więc coraz częściej działają na GPU lub wyspecjalizowanej infrastrukturze chmurowej. W takim środowisku trzeba zabezpieczać nie tylko klasyczny procesor i pamięć, ale również ścieżkę przetwarzania AI.
W praktyce oznacza to, że poufne przetwarzanie danych przesuwa się z klasycznego świata maszyn wirtualnych i procesorów CPU w stronę modeli językowych, inference, trenowania, dostrajania i obciążeń GPU.
AI potrzebuje danych. Firmy potrzebują kontroli. Poufne przetwarzanie danych ma pomóc pogodzić jedno z drugim.
Poufne przetwarzanie danych a chmura publiczna
Chmura publiczna daje skalowalność, elastyczność i dostęp do zaawansowanych usług. Jednocześnie zawsze wiąże się z pytaniem o zaufanie. Organizacja korzysta z infrastruktury, której fizycznie nie kontroluje. Ma umowy, certyfikaty, polityki bezpieczeństwa i szyfrowanie, ale nadal przetwarza dane na zasobach dostawcy.
Poufne przetwarzanie danych zmienia tę rozmowę. Nie usuwa konieczności zaufania do dostawcy chmury, ale ogranicza zakres tego zaufania. Zamiast zakładać, że wszystkie warstwy infrastruktury muszą być w pełni zaufane, organizacja może wymagać, aby najbardziej wrażliwe obliczenia odbywały się w środowisku sprzętowo izolowanym.
To szczególnie ważne dla firm, które dotąd niechętnie przenosiły najbardziej wrażliwe systemy do chmury. Część organizacji nie blokuje chmury z powodu braku funkcji, lecz z powodu obaw o kontrolę, zgodność, prywatność i odpowiedzialność.
Poufne przetwarzanie danych może być jednym z argumentów za przeniesieniem wybranych obciążeń do chmury, ale na bardziej rygorystycznych zasadach.
Nie oznacza to jednak, że wystarczy zaznaczyć jedną opcję w panelu chmurowym i uznać temat bezpieczeństwa za zamknięty. Nadal trzeba sprawdzić zarządzanie tożsamością, konfigurację sieci, dostęp administratorów, polityki kluczy, integracje, backupy, monitoring, logowanie, zarządzanie podatnościami i zgodność z regulacjami.
Poufne przetwarzanie danych jest mocną warstwą ochrony, ale nie zastępuje całej strategii cyberbezpieczeństwa.
Poufne przetwarzanie danych a zero trust
Zero trust i poufne przetwarzanie danych często pojawiają się w podobnym kontekście, ale nie oznaczają tego samego.
Zero trust to model bezpieczeństwa oparty na zasadzie: nie ufaj domyślnie, zawsze weryfikuj. Dotyczy użytkowników, urządzeń, aplikacji, sieci, tożsamości, uprawnień i dostępu do zasobów.
Poufne przetwarzanie danych jest technologią lub zestawem technologii, które mogą wspierać zero trust na poziomie przetwarzania informacji. Skoro zero trust zakłada ograniczanie zaufania, to poufne przetwarzanie danych idealnie pasuje do tego podejścia: nie ufamy całej infrastrukturze, tylko weryfikujemy konkretne środowisko wykonawcze.
Można to ująć tak: zero trust odpowiada na pytanie, kto i na jakich zasadach może uzyskać dostęp. Poufne przetwarzanie danych odpowiada na pytanie, jak chronić dane nawet wtedy, gdy są aktywnie przetwarzane w cudzej, współdzielonej lub złożonej infrastrukturze.
Najsilniejsze wdrożenia będą łączyć oba podejścia. Organizacja powinna kontrolować tożsamość, minimalizować uprawnienia, segmentować dostęp, monitorować zachowania i jednocześnie chronić najbardziej wrażliwe obliczenia w izolowanym środowisku.
Dopiero połączenie zero trust, szyfrowania, kontroli dostępu i poufnego przetwarzania danych daje nowoczesny, warstwowy model ochrony.
Poufne przetwarzanie danych a prywatność
Poufne przetwarzanie danych może mieć duże znaczenie dla prywatności, ale nie należy mylić go z pełną anonimizacją. Ta technologia nie sprawia automatycznie, że dane przestają być danymi osobowymi. Nie zwalnia też z obowiązków wynikających z RODO, regulacji sektorowych, umów powierzenia czy polityk bezpieczeństwa.
Może jednak pomóc w ograniczaniu ryzyka. Jeżeli dane osobowe, dane medyczne lub dane finansowe są przetwarzane w środowisku lepiej izolowanym i weryfikowalnym, organizacja może łatwiej wykazać, że stosuje środki techniczne adekwatne do charakteru ryzyka.
W praktyce poufne przetwarzanie danych powinno być częścią szerszej strategii obejmującej szyfrowanie, minimalizację danych, pseudonimizację, kontrolę dostępu, monitoring, polityki retencji, audyt, zarządzanie kluczami i bezpieczeństwo aplikacji.
Najlepszy efekt daje dopiero połączenie poufnego przetwarzania danych z dobrym governance AI, zero trust i świadomym zarządzaniem cyklem życia danych.
Najważniejsze zastosowania poufnego przetwarzania danych
Pierwszy obszar to AI i generatywna sztuczna inteligencja. Firmy chcą używać modeli AI na danych wewnętrznych, ale obawiają się wycieku promptów, dokumentów, wyników, danych treningowych lub własności intelektualnej. Poufne przetwarzanie danych może pomóc w uruchamianiu inference i analizy w środowiskach bardziej odpornych na podgląd z zewnątrz.
Drugi obszar to sektor finansowy. Banki, ubezpieczyciele, fintechy i operatorzy płatności przetwarzają dane transakcyjne, scoringowe, behawioralne i identyfikacyjne. Ujawnienie takich informacji może oznaczać poważne ryzyko regulacyjne, reputacyjne i finansowe.
Trzeci obszar to ochrona zdrowia. Dane pacjentów należą do najbardziej wrażliwych kategorii informacji. AI może wspierać analizę dokumentacji, obrazowania, wyników badań czy procesów administracyjnych, ale bez silnych zabezpieczeń trudno wdrażać takie rozwiązania na dużą skalę.
Czwarty obszar to administracja publiczna i dane obywateli. Państwo i samorządy przetwarzają ogromne zbiory danych osobowych. Poufne przetwarzanie danych może mieć znaczenie tam, gdzie usługi publiczne korzystają z chmury, AI lub współdzielonej infrastruktury.
Piąty obszar to przemysł, energetyka i infrastruktura krytyczna. Dane operacyjne, plany produkcji, parametry sieci, projekty techniczne i informacje o awariach mogą mieć znaczenie biznesowe, strategiczne i bezpieczeństwa państwa.
Szósty obszar to wspólna analiza danych między firmami. Kilka organizacji może chcieć uzyskać wspólny wynik analityczny, ale bez ujawniania sobie surowych danych. Poufne przetwarzanie danych może wspierać właśnie takie modele współpracy.
Czy poufne przetwarzanie danych oznacza, że dane są cały czas zaszyfrowane?
To częste uproszczenie. W praktyce poufne przetwarzanie danych nie oznacza, że każda operacja wykonywana jest na danych zaszyfrowanych w sensie matematycznym. Oznacza raczej, że dane są odszyfrowywane i przetwarzane wewnątrz chronionego, izolowanego środowiska.
Różnica jest istotna. Pełne szyfrowanie homomorficzne pozwala wykonywać obliczenia bez odszyfrowywania danych, ale w wielu zastosowaniach jest nadal kosztowne, skomplikowane i trudne do wdrożenia na dużą skalę. Poufne przetwarzanie danych wybiera inny kompromis: dane mogą być używane przez aplikację, ale środowisko, w którym są używane, jest izolowane i weryfikowalne.
To dlatego poufne przetwarzanie danych jest atrakcyjne biznesowo. W wielu przypadkach może być łatwiejsze do zastosowania w realnych systemach niż bardziej eksperymentalne techniki kryptograficzne.
Nie oznacza to jednak pełnej odporności na błędy. Jeżeli aplikacja sama zapisuje poufne dane w niezabezpieczonych logach, wysyła wyniki do nieautoryzowanych usług albo ma źle skonfigurowane uprawnienia, samo zaufane środowisko wykonawcze nie rozwiąże problemu.
Poufne przetwarzanie danych chroni ważny etap pracy z informacjami, ale nie naprawia złej architektury całego systemu.
Poufne przetwarzanie danych a platformy bezpieczeństwa AI
Wraz z rozwojem sztucznej inteligencji rośnie znaczenie platform bezpieczeństwa AI. Takie narzędzia mają monitorować użycie modeli, egzekwować polityki, ograniczać ryzyko wycieku danych, wykrywać nadużycia, kontrolować prompty i chronić przed zagrożeniami charakterystycznymi dla aplikacji AI.
Poufne przetwarzanie danych nie zastępuje takich platform. Nie zatrzyma automatycznie złego promptu. Nie naprawi błędnej polityki dostępu. Nie sprawi, że model przestanie halucynować. Nie zastąpi testów aplikacji, monitoringu ani kontroli agentów AI.
Można to ująć tak: platformy bezpieczeństwa AI pilnują zachowania, polityk i widoczności systemów AI, a poufne przetwarzanie danych wzmacnia zaufanie do środowiska, w którym dane i modele są przetwarzane.
Te dwa obszary nie konkurują ze sobą. Raczej się uzupełniają. W dojrzałej architekturze AI organizacja będzie potrzebowała zarówno kontroli dostępu, monitoringu i governance, jak i ochrony danych w użyciu.
Czy poufne przetwarzanie danych działa tylko w chmurze?
Nie. Chmura jest jednym z najważniejszych zastosowań, ale nie jedynym.
Poufne przetwarzanie danych ma szczególne znaczenie tam, gdzie infrastruktura jest współdzielona, zewnętrzna lub nie w pełni kontrolowana przez właściciela danych. Publiczna chmura jest naturalnym przykładem, bo firma korzysta z zasobów dostawcy, ale chce ograniczyć zaufanie do operatora infrastruktury.
Podobne mechanizmy mogą być jednak ważne również w środowiskach hybrydowych, edge computingu, centrach danych partnerów, systemach przemysłowych, sektorze publicznym, konsorcjach danych i projektach współdzielenia informacji między organizacjami.
Przykład? Kilka banków chce wspólnie trenować lub uruchamiać model wykrywania nadużyć, ale żaden z nich nie chce ujawniać pełnych danych transakcyjnych pozostałym uczestnikom. Albo kilka szpitali chce analizować dane medyczne w celu poprawy diagnostyki, ale bez tworzenia jednej, jawnej bazy dostępnej dla wszystkich.
Poufne przetwarzanie danych może umożliwiać współpracę na danych tam, gdzie wcześniej główną blokadą było zaufanie.
Czy poufne przetwarzanie danych wpływa na wydajność?
Tak, może wpływać. Każda dodatkowa warstwa ochrony może oznaczać pewien koszt. Izolacja, szyfrowanie pamięci, atestacja i dodatkowe mechanizmy bezpieczeństwa mogą wprowadzać narzut wydajnościowy.
Skala tego wpływu zależy od konkretnej architektury. Znaczenie mają: typ procesora, wykorzystanie GPU, długość zapytań, rodzaj workloadu, sposób ładowania modelu, intensywność operacji wejścia-wyjścia, komunikacja między komponentami i konfiguracja środowiska.
W części scenariuszy narzut może być niewielki. W innych może wymagać optymalizacji, zmiany architektury lub selektywnego użycia technologii tylko dla najbardziej wrażliwych operacji.
Najrozsądniejsze podejście polega na stosowaniu poufnego przetwarzania danych tam, gdzie wartość informacji i poziom ryzyka uzasadniają dodatkową warstwę ochrony.
Nie każdy workload jej potrzebuje. Publiczny chatbot FAQ oparty na jawnych treściach marketingowych prawdopodobnie nie wymaga takiej architektury. Ale analiza danych pacjentów, transakcji finansowych, dokumentów prawnych, danych klientów premium lub modeli stanowiących własność intelektualną firmy to zupełnie inna sytuacja.
Największe ograniczenia poufnego przetwarzania danych
Pierwsze ograniczenie to złożoność wdrożenia. Firmy muszą rozumieć, jak działa zaufane środowisko wykonawcze, atestacja, zarządzanie kluczami, polityki dostępu i integracja z istniejącą infrastrukturą.
Drugie ograniczenie to zależność od sprzętu i dostawców. Nie każda usługa, procesor, GPU, baza danych czy platforma AI wspiera poufne przetwarzanie danych w takim samym zakresie. Różnice między dostawcami mogą być duże.
Trzecie ograniczenie to wydajność i koszty. W wielu przypadkach narzut będzie akceptowalny, ale w części scenariuszy może wymagać testów, optymalizacji lub zmiany sposobu działania aplikacji.
Czwarte ograniczenie to brak ochrony przed wszystkimi błędami aplikacji. Jeżeli aplikacja ma podatność, źle zarządza dostępami albo wysyła wyniki do nieautoryzowanego systemu, sama enklawa tego nie naprawi.
Piąte ograniczenie to ryzyko fałszywego poczucia bezpieczeństwa. Poufne przetwarzanie danych jest mocną technologią, ale nie jest magiczną tarczą przed każdym cyberatakiem.
Największym błędem byłoby wdrażanie tej technologii bez całościowego modelu bezpieczeństwa.
Potrzebne są nadal: dobre projektowanie aplikacji, monitoring, testy, aktualizacje, kontrola uprawnień, polityki AI, zarządzanie sekretami, analiza ryzyka i szkolenia zespołów.
Dlaczego poufne przetwarzanie danych zyskuje na znaczeniu właśnie teraz?
Poufne przetwarzanie danych zyskuje na znaczeniu, ponieważ zmienił się sposób korzystania z danych. Organizacje coraz częściej korzystają z chmury publicznej, modeli AI, agentów, zewnętrznych API, rozproszonych usług i współdzielonej infrastruktury.
Dane nie są już zamknięte w jednej bazie na firmowym serwerze. Przepływają przez aplikacje, integracje, modele, hurtownie, platformy analityczne i systemy automatyzacji. Jednocześnie coraz więcej procesów biznesowych wymaga pracy na danych wrażliwych.
Do tego dochodzi presja regulacyjna. Firmy muszą nie tylko chronić dane, ale też wykazywać, że robią to w sposób kontrolowany. W sektorach takich jak finanse, zdrowie, administracja, energetyka czy ubezpieczenia samo zapewnienie, że „dane są bezpieczne”, może być niewystarczające.
Poufne przetwarzanie danych daje bardziej techniczną odpowiedź na pytanie, kto może zobaczyć dane wtedy, gdy są one faktycznie używane.
To właśnie dlatego technologia pojawia się w kontekście strategicznych trendów na najbliższe lata. Nie jest tylko kolejną funkcją bezpieczeństwa. Może stać się elementem infrastruktury potrzebnej do bezpiecznego wdrażania AI, analityki i chmury w najbardziej wymagających branżach.
Może Cię zainteresować: Serwery MCP – co to jest i jak zmieniają przyszłość agentów AI?
Co oznacza poufne przetwarzanie danych dla zwykłego użytkownika?
Dla zwykłego użytkownika poufne przetwarzanie danych będzie najczęściej niewidoczne. Nie jest to funkcja, którą klikamy w telefonie jak tryb ciemny, blokadę ekranu albo zgodę na lokalizację. To warstwa infrastruktury działająca pod spodem.
Skutki mogą być jednak bardzo konkretne.
Usługa bankowa może bezpieczniej analizować transakcje. Aplikacja medyczna może lepiej chronić dokumentację. System AI w firmie może przetwarzać poufne dane bez przekazywania ich w jawnej formie całej infrastrukturze. Usługa chmurowa może dawać większą kontrolę nad tym, kto i co może zobaczyć podczas przetwarzania.
Dla użytkownika końcowego najważniejsza korzyść to większa szansa, że jego dane nie będą narażone w najbardziej wrażliwym momencie: podczas aktywnego użycia.
Oczywiście nadal trzeba uważać, jakie dane wpisujemy do narzędzi AI, jakim usługom je powierzamy i jakie zgody akceptujemy. Poufne przetwarzanie danych nie zwalnia użytkownika ani firmy z rozsądku. Może jednak stać się ważną częścią infrastruktury, której użytkownik nie widzi, ale z której ochrony korzysta.
Jak firmy powinny przygotować się do poufnego przetwarzania danych?
Pierwszy krok to mapa danych. Firma powinna wiedzieć, gdzie znajdują się dane wrażliwe, kto ma do nich dostęp, w jakich procesach są używane i które systemy przetwarzają je w chmurze lub przez AI.
Drugi krok to klasyfikacja workloadów. Nie wszystko wymaga poufnego przetwarzania danych. Najpierw warto wybrać procesy o najwyższym ryzyku: dane medyczne, finansowe, prawne, dane klientów, tajemnice przedsiębiorstwa, modele AI, dane treningowe i dokumenty strategiczne.
Trzeci krok to analiza dostawców. Trzeba sprawdzić, jakie mechanizmy poufnego przetwarzania danych oferuje dana chmura, platforma AI, baza danych, środowisko kontenerowe lub infrastruktura GPU.
Czwarty krok to zarządzanie kluczami. Bez dobrego zarządzania kluczami nawet najlepsze środowisko zaufane nie rozwiąże problemu bezpieczeństwa.
Piąty krok to integracja z governance AI. Jeżeli firma wdraża modele językowe, agentów lub systemy RAG, powinna połączyć poufne przetwarzanie danych z politykami dostępu, monitoringiem promptów, rejestrowaniem operacji, ochroną przed wyciekiem danych i testami bezpieczeństwa.
Szósty krok to testy wydajności i kosztów. Wdrożenie powinno być sprawdzone na rzeczywistych danych, rzeczywistych modelach i rzeczywistych obciążeniach.
Najlepiej zaczynać od jednego konkretnego przypadku użycia, a nie od wielkiej migracji całej infrastruktury.
Poufne przetwarzanie danych a przyszłość AI
W najbliższych latach AI będzie przetwarzać coraz bardziej wrażliwe dane. Modele będą coraz częściej działać nie jako osobne chatboty, ale jako warstwa operacyjna firm. Będą analizować dokumenty, podejmować rekomendacje, uruchamiać procesy, obsługiwać klientów, wspierać programistów, kontrolować dane produkcyjne i współpracować z innymi agentami.
To oznacza, że organizacje będą musiały odpowiedzieć na trudne pytania.
Czy możemy przekazać dane klientów do modelu AI? Czy możemy analizować dokumenty prawne w chmurze? Czy możemy trenować model na danych z kilku firm? Czy możemy używać AI w medycynie bez ryzyka naruszenia prywatności pacjentów? Czy możemy udowodnić, że dane były przetwarzane tylko przez zweryfikowany kod? Czy możemy ograniczyć zaufanie do operatora infrastruktury?
Poufne przetwarzanie danych nie jest pełną odpowiedzią na wszystkie pytania, ale może być jednym z najważniejszych elementów tej odpowiedzi.
W świecie, w którym AI potrzebuje coraz więcej danych, najcenniejsze staną się technologie pozwalające używać informacji bez niepotrzebnego ich ujawniania. To właśnie tutaj poufne przetwarzanie danych ma największy potencjał.
Może Cię zainteresować: AI-native development platforms – jak AI zmienia programowanie w 2026 roku?
Poufne przetwarzanie danych – najważniejsze wnioski
Poufne przetwarzanie danych chroni dane w użyciu, czyli wtedy, gdy są aktywnie przetwarzane przez aplikację, procesor, model AI lub system analityczny. To uzupełnienie klasycznego szyfrowania danych w spoczynku i w transmisji.
Technologia opiera się na zaufanym środowisku wykonawczym, czyli sprzętowo izolowanym obszarze, który ogranicza dostęp do danych i kodu poza chronioną enklawą. Ważnym elementem jest również atestacja, pozwalająca potwierdzić, że dane trafiły do właściwego, zweryfikowanego środowiska.
Dla AI znaczenie tej technologii rośnie szczególnie szybko. Modele generatywne, agenci AI, systemy RAG i branżowe modele językowe coraz częściej pracują na danych wrażliwych, prywatnych lub strategicznych. Bez ochrony danych w użyciu trudno będzie bezpiecznie skalować AI w sektorach regulowanych.
Poufne przetwarzanie danych nie zastępuje RODO, zero trust, AI governance, kontroli dostępu ani platform bezpieczeństwa AI. Może jednak stać się jedną z kluczowych warstw technicznych, które umożliwią bardziej zaufane przetwarzanie informacji w chmurze i środowiskach współdzielonych.
Najważniejsza zmiana polega na przesunięciu myślenia: firmy nie mogą już chronić tylko danych zapisanych i przesyłanych. W erze AI trzeba chronić również ten moment, w którym dane faktycznie pracują.
FAQ – poufne przetwarzanie danych
Co to jest poufne przetwarzanie danych?
Co oznacza angielski termin confidential computing?
Dlaczego poufne przetwarzanie danych jest ważne dla AI?
Czy poufne przetwarzanie danych zapobiega wyciekom danych z AI?
Czy poufne przetwarzanie danych zastępuje tradycyjne szyfrowanie?
Dziękujemy za przeczytanie artykułu na Techoteka.pl.
Publikujemy codziennie informacje o sztucznej inteligencji, nowych technologiach, IT oraz rozwoju agentów AI.
Obserwuj nas na Facebooku, aby nie przegapić kolejnych artykułów.


