
19 lutego 2026 roku Google DeepMind udostępniło w wersji preview swój najnowszy model flagowy – Gemini 3.1 Pro. To ruch szybki nawet jak na dzisiejsze tempo rozwoju AI. Poprzednia wersja zadebiutowała w listopadzie 2025 roku. Minęły zaledwie trzy miesiące – i dostajemy znaczący upgrade.
Nie jest to kosmetyczna aktualizacja. Gemini 3.1 Pro to odpowiedź Google na przyspieszenie wyścigu wśród modeli klasy frontier – szczególnie po premierach modeli Anthropic i OpenAI z przełomu 2025/2026 roku. Pytanie brzmi: czy to realny skok jakościowy, czy tylko marketingowa iteracja?
Na podstawie dokumentacji technicznej, benchmarków i dostępnych danych – wygląda na to, że tym razem mamy do czynienia z czymś więcej niż tylko drobną poprawką.
Czym jest Gemini 3.1 Pro?
Gemini 3.1 Pro to najnowszy model z linii Pro rozwijanej przez Google DeepMind, udostępniony w wersji preview 19 lutego 2026 roku. Plasuje się powyżej standardowych modeli Gemini, a jednocześnie poniżej elitarnego, dostępnego wyłącznie na zaproszenie poziomu Deep Think.
Model ten obejmuje szeroki „środkowy segment” stosu AI Google — czyli obszar, w którym realizowana jest większość rzeczywistych zastosowań biznesowych i deweloperskich.
Warto zwrócić uwagę na samo nazewnictwo. To pierwszy przypadek, gdy Google zastosowało oznaczenie „.1” zamiast „.5”. Sugeruje to, że skok możliwości jest istotny, ale nie stanowi pełnoprawnej zmiany generacyjnej. Można to traktować jako precyzyjny, ukierunkowany upgrade, a nie całkowitą przebudowę modelu.
Istotny kontekst dotyczy także samej architektury inteligencji. Rdzeń zastosowany w Gemini 3.1 Pro jest bezpośrednio powiązany z rozwiązaniami rozwijanymi w ramach Deep Think. Google określa wersję 3.1 Pro jako model wyposażony w „zaktualizowaną rdzeniową inteligencję”, która umożliwia przełomy w rozumowaniu znane z Deep Think — teraz udostępnione szerokiemu ekosystemowi deweloperów i przedsiębiorstw.

Co faktycznie zmieniło się względem Gemini 3 Pro
Różnica między Gemini 3 Pro a 3.1 Pro nie jest kosmetyczna. Najczęściej przywoływaną liczbą jest wynik w teście ARC-AGI-2:
31,1% dla Gemini 3 Pro
77,1% dla 3.1 Pro
Ten benchmark sprawdza zdolność modelu do rozwiązywania wzorców logicznych, których nigdy wcześniej nie widział. To istotny wskaźnik realnego rozumowania, a nie zapamiętywania danych.
Jednak poza nagłówkową liczbą są trzy konkretne zmiany, które realnie wpływają na sposób korzystania z modelu.
Trójpoziomowe poziomy „Thinking”
Można teraz ustawić głębokość rozumowania dla każdego zapytania: Low, Medium lub High. Tryb High działa jak pomniejszona wersja Deep Think — wykorzystuje wyraźnie więcej mocy obliczeniowej przy trudnych problemach.
Lepsza wydajność agentowa
Wynik w teście MCP Atlas, który mierzy wieloetapowe korzystanie z narzędzi, wzrósł o 15 punktów procentowych względem Gemini 3 Pro.
Dedykowany endpoint dla własnych narzędzi
Jeśli workflow łączy wykonywanie poleceń bash z własnymi narzędziami, endpoint gemini-3.1-pro-preview-customtools nadaje im wyższy priorytet i działa bardziej przewidywalnie niż standardowa wersja API.
Największe znaczenie praktyczne ma jednak trójpoziomowy system rozumowania. Pozwala uruchamiać lekkie zapytania niskim kosztem i rezerwować tryb High tylko dla zadań, które rzeczywiście tego wymagają — wszystko w ramach jednej integracji modelu.
Gemini 3.1 Pro – obraz benchmarków
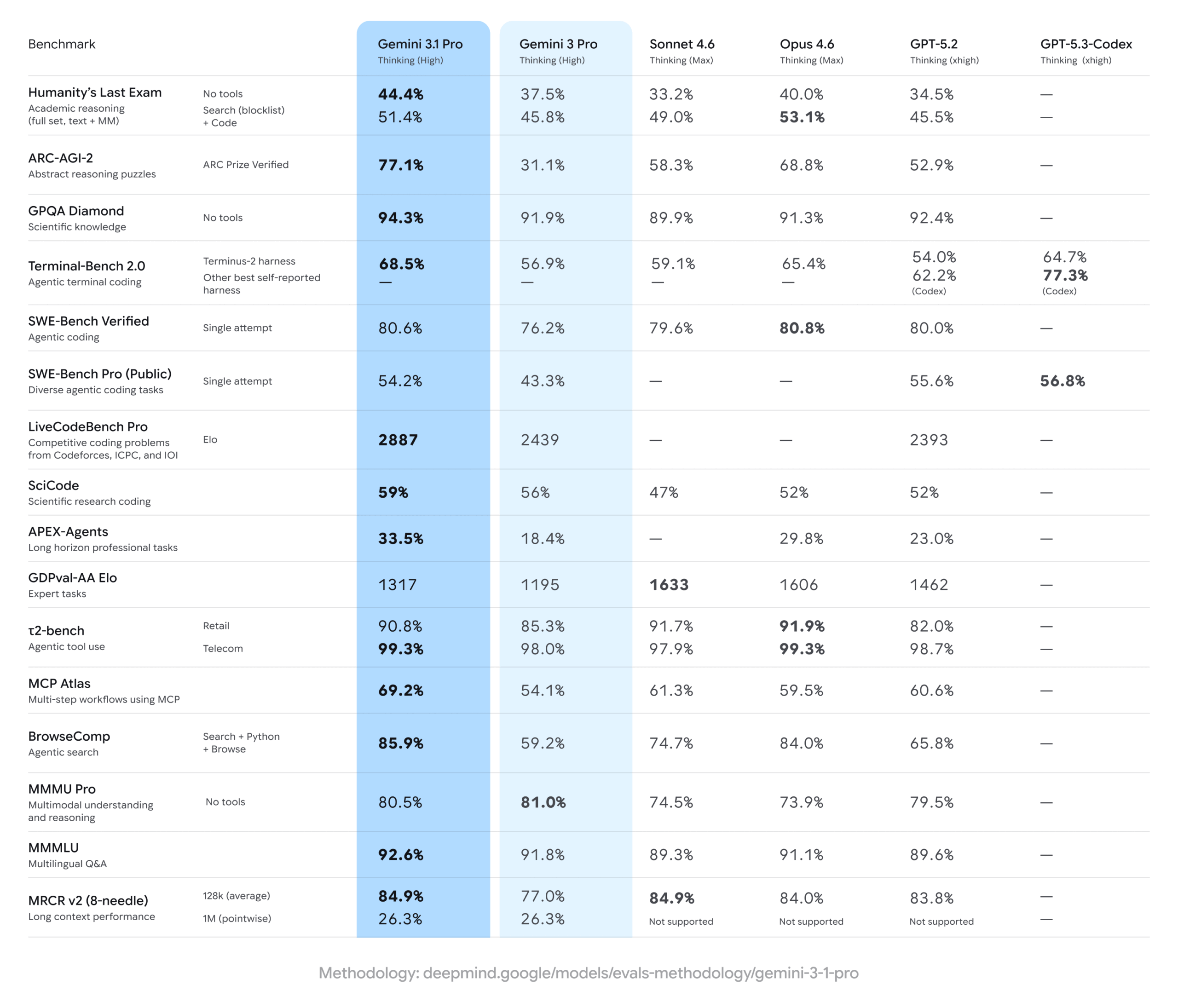
Same liczby bez kontekstu niewiele mówią. Dlatego warto przełożyć wyniki na praktykę — co one realnie oznaczają w codziennej pracy z modelem.
Rozumowanie
Wynik 77,1% w ARC-AGI-2 plasuje 3.1 Pro wyraźnie przed GPT-5.2 (52,9%) oraz Claude Opus 4.6 (68,8%) w tym konkretnym teście.
To benchmark mierzący zdolność rozwiązywania zupełnie nowych wzorców logicznych. Innymi słowy — test prawdziwego rozumowania, a nie pamięci treningowej.
Nauka i wiedza ekspercka
GPQA Diamond to zestaw pytań tworzonych przez ekspertów z zakresu fizyki, chemii i biologii. Wynik 94,3% daje pierwsze miejsce wśród publicznie ocenianych modeli.
Dla środowisk badawczych, analitycznych i zespołów tworzących dokumentację techniczną ma to realne znaczenie — model nie tylko „odpowiada”, ale utrzymuje wysoki poziom merytoryczny w specjalistycznych dziedzinach.
Programowanie
LiveCodeBench Pro wykorzystuje aktualne zadania konkursowe, które nie występowały w danych treningowych. Skok do 2887 Elo (z 2439 w Gemini 3 Pro) to duży wzrost zdolności generalizacji.
W SWE-Bench Verified — czyli teście opartym na rzeczywistych zadaniach inżynierii oprogramowania — model osiągnął 80,6%.
Gdzie 3.1 Pro nie jest liderem?
Warto uczciwie zaznaczyć obszary, w których model nie zajmuje pierwszego miejsca.
-
W MMMU Pro (zaawansowane rozumowanie multimodalne) Gemini 3 Pro (81,0%) minimalnie wyprzedza 3.1 Pro (80,5%).
-
Claude Sonnet 4.6 zajmuje pierwsze miejsce w GDPval-AA Elo (1633). Gemini 3.1 Pro uzyskał 1317 — to poprawa względem poprzednika, ale wynik niższy niż u Claude i OpenAI.
-
GPT-5.3-Codex (xhigh) prowadzi w Terminal-Bench 2.0 oraz SWE-Bench Pro — benchmarkach skoncentrowanych na bardziej wyspecjalizowanych zadaniach programistycznych.
Podsumowanie benchmarków
Łącznie 3.1 Pro zajmuje pierwsze miejsce w 12 z 16 monitorowanych benchmarków.
To bardzo mocny rezultat. Nie oznacza dominacji absolutnej w każdej kategorii, ale pokazuje, że model oferuje obecnie jeden z najlepszych — jeśli nie najlepszy — zbiorczy poziom wydajności w swojej klasie.
Dla kogo model Gemini 3.1 Pro został faktycznie zbudowany?
Wyniki benchmarków dają dobre wyobrażenie o możliwościach modelu, ale nie oznaczają, że sprawdzi się on w każdym scenariuszu. Przy wyborze modelu kluczowe nie powinny być same liczby, lecz to, czy realnie odpowiada on na konkretne potrzeby zespołu.
Deweloperzy
Najbardziej oczywistym odbiorcą są deweloperzy budujący systemy agentowe i złożone pipeline’y decyzyjne.
Wyraźny wzrost niezawodności w wieloetapowym użyciu narzędzi, dedykowany endpoint customtools oraz możliwość regulowania głębokości rozumowania sprawiają, że model dobrze sprawdza się w workflow wymagających ciągłego podejmowania decyzji na wielu etapach — a nie jednorazowych odpowiedzi.
To ważna różnica. W systemach agentowych stabilność bywa cenniejsza niż pojedynczy, imponujący wynik.
Zespoły inżynieryjne
Model jest również mocnym kandydatem dla zespołów z intensywnym obciążeniem programistycznym. Wynik w LiveCodeBench Pro opiera się na zadaniach, które nie występowały w danych treningowych, co oznacza zdolność generalizacji, a nie odtwarzania wzorców.
W kontekście code review, refaktoryzacji czy analizy architektury całego systemu kluczowe znaczenie ma okno kontekstowe 1 miliona tokenów. Pozwala ono pracować na pełnym repozytorium bez konieczności dzielenia projektu na mniejsze fragmenty.
To zmienia sposób współpracy modelu z zespołem technicznym.
Badacze i zespoły wiedzochłonne
Trzeci naturalny obszar zastosowań to środowiska badawcze oraz zespoły pracujące na wiedzy eksperckiej. Wysoki wynik w GPQA Diamond wskazuje na zdolność utrzymywania złożonej wiedzy domenowej i stosowania jej w zadaniach, które bywają trudne nawet dla specjalistów.
Dla R&D, analiz naukowych czy dokumentacji technicznej to realna przewaga.
Zespoły z ograniczonym budżetem
Na koniec kwestia kosztów. Przy cenie około 2 USD za milion tokenów wejściowych model jest znacząco tańszy niż Claude Opus 4.6 (około 15 USD za milion), oferując przy tym porównywalne lub lepsze wyniki w większości benchmarków.
Dla zespołów wrażliwych na budżet to nie detal, lecz argument strategiczny.
Jak zacząć pracę z modelem Gemini 3.1 Pro
Uzyskanie dostępu jest stosunkowo proste — wszystko zależy od tego, w jakim trybie chcesz pracować z modelem.
Google AI Studio
To najszybszy punkt startowy. Nie wymaga konfiguracji klucza API, działa bezpłatnie w ramach określonych limitów i pozwala testować model bezpośrednio w przeglądarce — zanim napiszesz choć jedną linijkę kodu.
Dla zespołów, które chcą najpierw sprawdzić możliwości modelu w praktyce, to naturalny pierwszy krok.
Gemini API
Ścieżka dla wdrożeń produkcyjnych. W tym przypadku kluczowe są dwa identyfikatory modeli:
-
gemini-3.1-pro-preview— do zastosowań ogólnych -
gemini-3.1-pro-preview-customtools— dla workflow agentowych z własnymi definicjami narzędzi
Drugi endpoint jest szczególnie istotny, jeśli aplikacja łączy model z własnymi narzędziami, skryptami bash czy zewnętrznymi systemami.
Optymalizacja kosztów: context caching
Jednym z elementów, o którym warto pomyśleć już na etapie projektowania architektury, jest mechanizm context caching.
Jeśli aplikacja wielokrotnie odwołuje się do tego samego, rozbudowanego kontekstu — np. bazy wiedzy, rozbudowanego promptu systemowego czy obszernego dokumentu — jego buforowanie może znacząco obniżyć koszty przetwarzania.
W praktyce oznacza to bardziej przewidywalny budżet i większą skalowalność rozwiązania.
Jak wypada Gemini 3.1 Pro na tle konkurencji
Porównania modeli klasy frontier mają sens tylko wtedy, gdy są konkretne. Ogólne stwierdzenia w stylu „ten jest lepszy” niewiele mówią. Spójrzmy więc na dane.
W starciu z Claude Opus 4.6
Gemini 3.1 Pro prowadzi w testach:
-
ARC-AGI-2
-
GPQA Diamond
-
MCP Atlas
-
BrowseComp
-
LiveCodeBench Pro
Z kolei Claude Opus 4.6 utrzymuje przewagę w GDPval-AA Elo oraz w części wyspecjalizowanych benchmarków programistycznych.
Jeśli kluczowym kryterium są oceny preferencji ekspertów w zadaniach wymagających „ludzkiego” osądu jakości — Opus 4.6 wciąż ma mocną pozycję.
Jeśli jednak optymalizujesz relację wydajność–cena i patrzysz na przekrojowe wyniki benchmarków, Gemini 3.1 Pro wypada bardzo konkurencyjnie.
W porównaniu z GPT-5.2
Gemini 3.1 Pro wyraźnie prowadzi w benchmarkach rozumowania oraz testach agentowych.
Specjalizowany wariant GPT-5.3-Codex dominuje natomiast w Terminal-Bench 2.0 oraz wybranych zaawansowanych testach inżynierii oprogramowania.
Dla zastosowań ogólnych przewaga przechyla się na stronę Gemini. W przypadku głębokiej infrastruktury kodowej, środowisk terminalowych i bardzo wyspecjalizowanych zadań developerskich — GPT-5.3-Codex może być wart przetestowania.
Wniosek praktyczny
Nie istnieje jeden model, który wygrywa w każdym scenariuszu.
To, co oferuje Gemini 3.1 Pro, to obecnie jeden z najsilniejszych łącznych wyników benchmarkowych w swojej klasie cenowej. Dla wielu zespołów oznacza to najlepszy kompromis między wydajnością, elastycznością a kosztem wdrożenia.
Ograniczenia Gemini 3.1 Pro, które warto znać przed wdrożeniem
Zanim zdecydujesz się oprzeć produkcyjne rozwiązanie na tym modelu, warto mieć świadomość kilku istotnych kwestii.
Knowledge cutoff – styczeń 2025
Granica wiedzy modelu została ustawiona na styczeń 2025 roku. W praktyce oznacza to, że w przypadku zadań dotyczących bieżących wydarzeń, najnowszych publikacji czy świeżych zmian technologicznych konieczne będzie włączenie Search Grounding albo zastosowanie zewnętrznej warstwy retrieval (RAG).
Bez tego model będzie operował wyłącznie na wiedzy historycznej.
Status preview – realne konsekwencje
Model jest obecnie w fazie preview. To nie tylko formalność.
Google nadal dopracowuje zachowanie systemu w oparciu o feedback deweloperów. W efekcie mogą pojawiać się:
-
niespójności w jakości odpowiedzi,
-
drobne różnice w zachowaniu API,
-
zmiany parametrów przed wersją GA (General Availability).
W środowiskach, gdzie kluczowa jest powtarzalność i stabilność wyników, budowanie systemu na wersji preview wiąże się z określonym ryzykiem.
Różnice między API a AI Studio
Istnieje również znana różnica w zachowaniu modelu pomiędzy standardowym endpointem API a środowiskiem Google AI Studio.
W AI Studio model może rozdzielać wynik na wiele plików, co w niektórych zadaniach przekłada się na wyższą jakość i lepszą strukturę odpowiedzi.
Natomiast przy ograniczeniu do jednego pliku wyjściowego — na przykład w przypadku generowania pojedynczego skryptu — ten sam model może wypaść słabiej niż w mniej restrykcyjnym środowisku.
To nie kwestia inteligencji, lecz ograniczeń wykonawczych i sposobu orkiestracji wyjścia.
Krótko mówiąc: możliwości są imponujące, ale jak w przypadku każdego modelu frontier, wdrożenie wymaga świadomej architektury i testów w realnym środowisku produkcyjnym.
Wnioski końcowe
Gemini 3.1 Pro to realny krok naprzód względem poprzednika. Skok w zakresie rozumowania jest poparty jednym z największych wzrostów benchmarkowych w historii tej linii modeli, cena pozostaje bez zmian, a nowy system „thinking” daje praktyczną kontrolę nad balansem koszt–jakość przy każdym zapytaniu.
Nie jest to jednak rozwiązanie uniwersalne.
W części wyspecjalizowanych benchmarków programistycznych GPT-5.3-Codex pozostaje lepszym narzędziem. W zadaniach ocenianych pod kątem preferencji eksperckich Claude Opus 4.6 nadal ma mocną pozycję.
Jednak dla zespołów budujących systemy agentowe, przetwarzających obszerne dokumenty lub potrzebujących rozumowania klasy frontier bez konieczności każdorazowego uzasadniania budżetu przed działem finansowym — to obecnie jedno z najbardziej praktycznych rozwiązań dostępnych na rynku.
FAQ – Gemini 3.1 Pro
Czym jest Gemini 3.1 Pro?
Czym jest ARC-AGI-2 i dlaczego wszyscy o nim mówią?
Jak Gemini 3.1 Pro wypada na tle Claude Sonnet 4.6?
W czym Gemini 3.1 Pro jest najlepszy?
Jak uzyskać dostęp do Gemini 3.1 Pro?
Czym jest context caching i czy warto to wdrożyć?
Śledź techoteka.pl i bądź na bieżąco z nowinkami technologicznymi! Obserwuj nas na Facebooku.



